- Blog
Fake Future #2: AI-generated synthetic images

Oliver Kampmeier
Cybersecurity Content Specialist
In our “Fake Future” series of articles, we want to look at new technologies that have the potential to fundamentally define the future.
In our last article, we focused on deepfake videos. How they are created, what use cases there are and what the current legal situation is.
This article highlights the use of artificial intelligence in conjunction with images. We elaborate on different levels of AI until we finally get to synthetic images, i.e. images that have been completely created by a computer.
Since the creation of synthetic images is similar in many parts to the creation of deepfake videos, you should definitely read our last article if you want to get detailed information about it.

What are AI-generated / synthetic images?
The definition of computer-generated imagery (CGI) can be interpreted very broadly. In film productions, the term CGI refers to visual special effects created by a human with the help of a computer.
AI-generated images are also created using a computer, but represent a subcategory of computer-generated images. The difference with CGI is the lack of human interaction in the creation of the images.
For example, a computer program can be trained on faces until it is finally able to “invent” and output a human face itself. This is exactly the use case of the website thispersondoesnotexist.com, which displays a real-looking profile picture of a human being when accessed. However, as the name of the website suggests, the individuals depicted do not exist. The algorithm was trained with profile pictures of real people until it was able to recreate a fictitious face true to reality and thus create the profile picture of a completely new person.
There are now also a variety of programs that can create images based on a simple text description. You describe to the program with words what you want to see and the tool automatically creates the image.
This is why the images are also referred to as synthetic. Unlike real images, which are captured by an imaging device such as a camera and then converted into pixels, synthetic images are created by pure computation, i.e. by modeling the real world and simulating the laws of optics.
How are synthetic images created?
Similar to creating deepfake videos, synthetic images are created by using Generative Adversial Networks (GANs), Autoencoders or the more sophisticated Vector Quantized Variational Autoencoders (VQ-VAE).
We do not want to go into too much detail about the different methods here, as it gets very scientific and mathematical rapidly. If you want to know more about GANs and autoencoders and how they work, you can read our article about deepfake videos, where we briefly explain how they work.
If you want to learn more about VQ-VAEs and are not afraid of mathematical formulas, we recommend the following great articles on the topic:
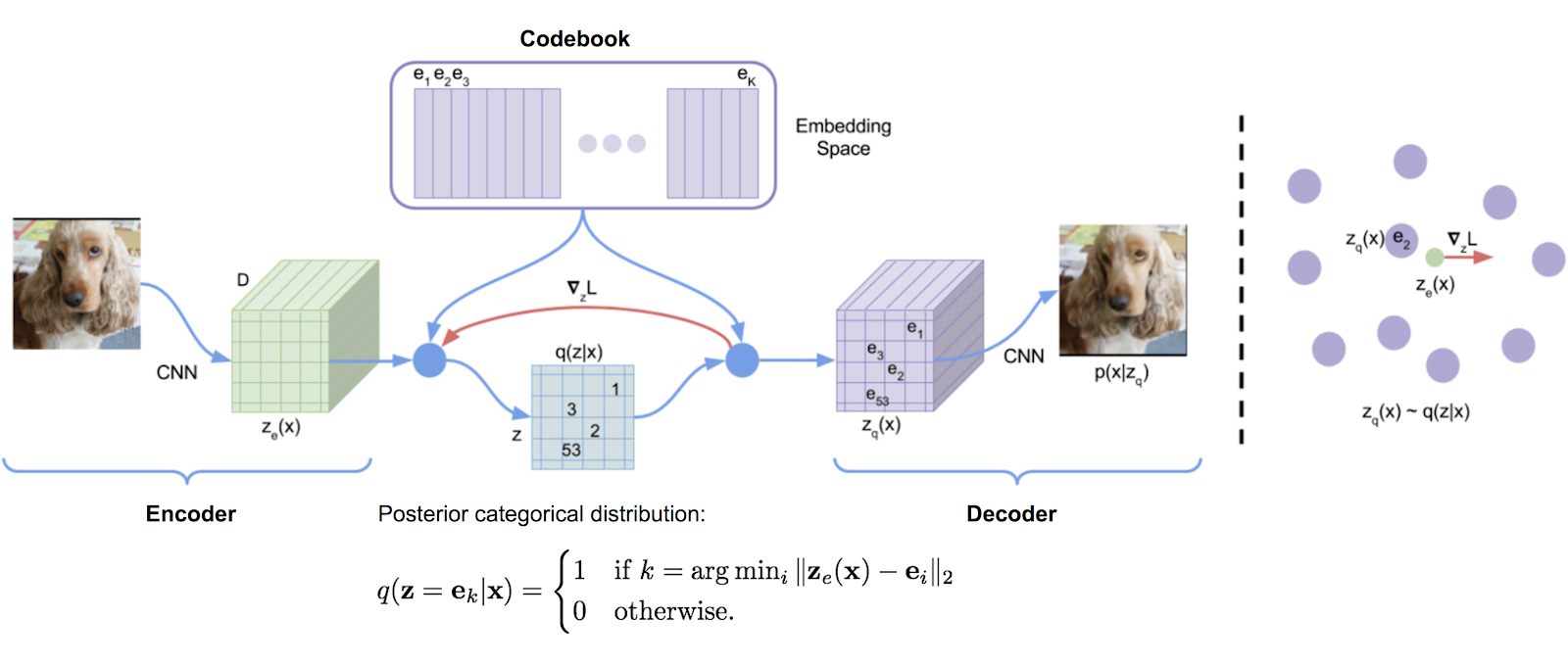
The main thing to understand is that the computer uses a form of unsupervised learning, which is a type of algorithm that learns patterns on its own without any human explaining or tagging the input data.
Use cases and examples of artificial intelligence in combination with images
There are a variety of use cases where artificial intelligence is used in conjunction with images.
Simple use cases include facial recognition or the automatic adjustment of the settings to match the lighting conditions in your smartphone camera app. Little helpers that are taken for granted nowadays and are indispensable for many of us.
In order to illustrate the various possible applications of AI, we will provide some examples below. Not all examples include synthetic images, but are intended to illustrate the different levels of artificial intelligence used.

Photo editing and enhancing
When the first photograph was captured by a camera in 1826, it did not take too long for the first manipulated image to be created.
In 1860, a photograph of the politician John Calhoun was manipulated and his body was used in another photograph with the head of the President of the United States, Abraham Lincoln.
Nowadays, image editing is a natural process. Whether it’s after a professional shoot or grandma’s vacation pictures, our images go through several optimization procedures, some of which are done automatically and with the help of artificial intelligence.
Automatic image manipulation includes the removal of unwanted objects in conjunction with content-aware fills, color enhancements and perspective warping.
In recent years, more and more AI-based tools and functions have found their way into Photoshop, the most widely used image editing program.
But the competition is not asleep either. There are now photo editing tools that explicitly advertise the functions of their artificial intelligence and highlight them as a unique selling point.
LuminarAI is such an AI-powered photo editor and promises its users some mind-blowing features like automated face and skin editing, changing the eye color, removing of freckles, and even changing skies with complete scene relighting.
Other use cases can be found at Hotpot.ai. Its tools can not only automatically remove backgrounds (see also remove.bg), but also restore color from black-and-white photos or use artificial intelligence to remove scratches and sharpen colors from old photos.
Topazlabs focuses on three other application areas:
- Noise and artifact removal, which are particularly visible in images taken at high ISO values
- Upscaling of images to be able to use them in high resolution, e.g. on posters
- Correction of lens blur and motion blur to obtain razor-sharp images
As you can see, there are no limits to the possible use cases of artificial intelligence in image editing today.

Camera assistants to improve photography
However, there is not only the possibility to edit pictures afterwards with the help of artificial intelligence, but to use it already during the shooting. Our second level of AI in conjunction with images are smart cameras and camera gadgets.
Arsenal markets its product as an intelligent camera assistant that helps photographers capture the perfect image. It does this by using a neural network to intelligently develop each photo. It generates a series of adjustments specifically tailored to each photo, responsible for powerful images without being over the top.
Furthermore, it also assists with panorama and long exposure shots and can automatically remove people or other moving objects from images by combining multiple shots.
Arsenal was able to collect over $2.5 million via Kickstarter. The successor Arsenal 2 even managed to raise over $4 million.
The market for smart camera assistants is still relatively new, which is why we can expect more products and innovations in the upcoming years.
Google took a slightly different approach a few years ago when they introduced Google Clips. A smart camera, much smaller than a GoPro, that automatically detects the best time to take a photo. This way, no beautiful moment should be missed because it takes too long to pull out the camera or smartphone.
Users should simply place the camera anywhere and no longer have to worry about taking pictures. Still, pictures can be taken manually at any time via a shutter button or the smartphone app.
Google’s people recognition algorithms work inside, automatically recognizing familiar faces and interesting activities and shooting several pictures at the appropriate moment, which are then stitched together into a 7-second “clip”.
Unfortunately, the product was quickly ditched and discontinued. It might have been partly because the first testers were not fully satisfied. Both the image quality (among other things, only 12 megapixels were installed) and the automatic trigger were not compelling.
However, the product clearly shows the direction in which cameras are developing. In the future, it may no longer be necessary to use a manual shutter release; instead, the camera will decide for itself when the best time to take a photo is.

See what’s hidden: from the quality of website traffic to the reality of ad placements. Insights drawn from billions of data points across our customer base in 2024.

Neural style transfer
The third level we want to highlight are a family of algorithms called Neural Style Transfer (NST).
“Neural style transfer is an optimization technique used to take two images – a content image and a style reference image (such as an artwork by a famous painter) – and blend them together so the output image looks like the content image, but “painted” in the style of the style reference image.” (TensorFlow)
You may have seen the Mona Lisa painted in the style of van Gogh. This was achieved through NST algorithms.
Identify objects and people
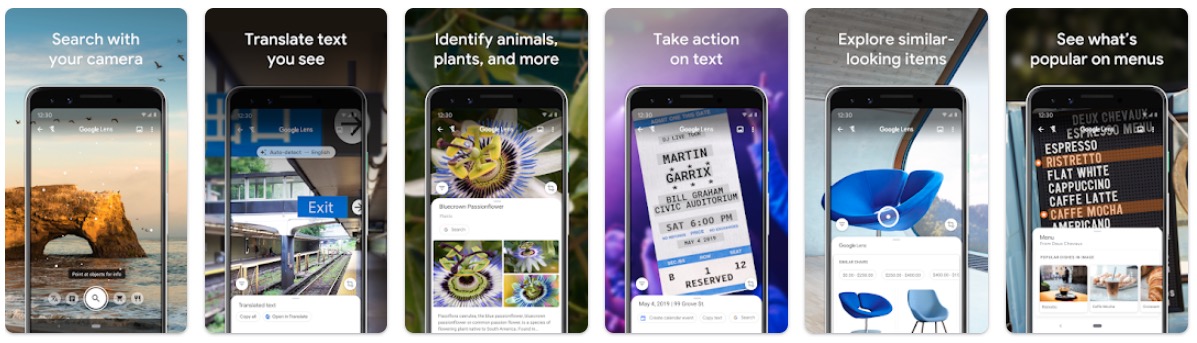
Aside from photo creation and editing, artificial intelligence can also be used to recognize objects in photos. One of the most prominent examples is Google Lens (Android | iOS). Based on an image, the app is able to:
- Perform a search for an object, such as a landmark or similar pieces of furniture
- Translate text on the image into multiple languages
- Identify animals, plants, food and much more
- Perform certain actions, such as automatically connecting to a Wi-Fi network when a corresponding QR code is photographed
- and much more
While Google Lens is an all-in-one solution, there are apps that specialize in detecting specific objects. One such example is the PictureThis: Plant Identifier app (Android | iOS), which can be used to identify various plants and flowers.
Another example is Bird Buddy and Birdfy, which both can be used to identify bird species that are present at your birdhouse.
All apps work on a similar principle: artificial intelligence has been trained to recognize specific objects in images using a large data set. Google gives us the following information about how Google Lens works:
“Lens compares objects in your picture to other images, and ranks those images based on their similarity and relevance to the objects in the original picture. Let’s say that Lens is looking at a dog that it identifies as probably 95% German shepherd and 5% corgi. In this case, Lens might only show the result for a German shepherd, which Lens has judged to be most visually similar.” (Google)
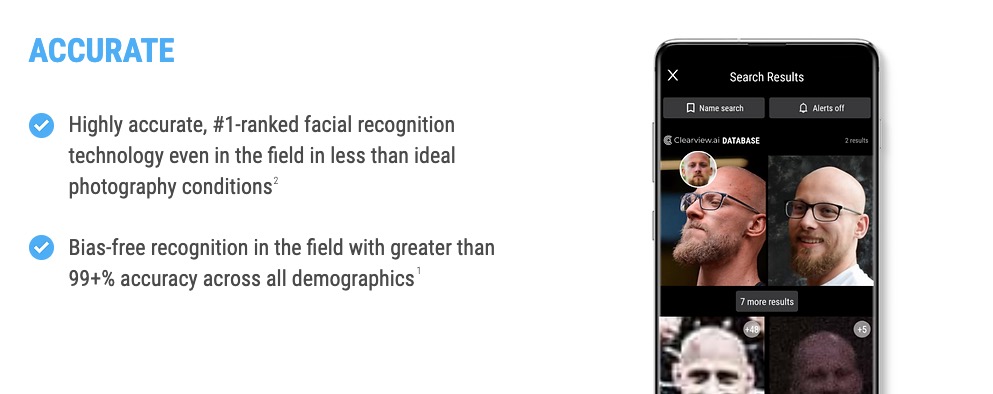
While the recognition of animals or plants can be quite useful in certain situations but should not have any major consequences beyond that, the situation is completely different for the automatic facial detection of people.
The company Clearview.ai has been collecting profile images from publicly available sources on the internet for several years and has, according to its own information, collected over 20 billion images in its database. The company has expressed to its investors that it is on track to expand the inventory to over 100 billion by the end of 2022, having an image of every person in the world in its database.
Clearview AI worked with more than 600 law enforcement agencies in the past, including the Federal Bureau of Investigation (FBI) and the Department of Homeland Security (DHS).
While cooperation with law enforcement agencies does not sound bad at first, misuse and access to the technology by private companies could have fatal consequences. For example, employees who were at a demonstration could fear negative consequences if their employer has access to the database. Likewise, misidentification could have fatal consequences for innocent people.
Autocratic governments’ access to the database can also result in greater surveillance and repression of the population.
Recently, the company has received a series of fines worth millions of dollars, as the collection of profile pictures took place without the consent of the affected individuals, thus violating existing data protection laws:
- UK’s Information Commissioner’s Office (ICO) fined Clearview AI over $9 million
- The Greek data protection authority has fined the company €20 million
- The French authority CNIL ordered the company to stop reusing photographs available on the internet
- The Italian data protection authority has fined Clearview AI also €20 million
- Australia has found that the company broke national privacy laws and ordered them to delete the data
- And also Canadian privacy authorities ruled the software illegal
Time will tell whether and how the company survives the current situation. In view of the large number of scandals, however, it should already be clear how controversial the use of such software is.
Text-to-image
The last example we would like to mention is also the most abstract and sophisticated. Artificial intelligence has become so advanced that it can not only understand and interpret texts, but also create a complete image based solely on a text description.
An oil painting of a Shiba Inu wearing a cowboy hat and a red T-shirt, riding a bike on the beach? No problem, here you go:

Or would you prefer a photorealistic image of an astronaut riding a horse on the moon?

There are no longer any limits to creativity.
At the moment, several companies are working on artificial intelligence that is able to create an image from just a text. The best-known representatives include OpenAI’s DALL-E and Google’s Imagen, which are currently competing for the best results.
The following video explains in an understandable way how the software works. It is trained on images from the internet that have a descriptive text. This way the AI understands the connection between text and the corresponding image. Over time, the program is able to abstract and thus link objects together so that we can enjoy a bass-playing polar bear.
Both DALL-E and Imagen are not yet available to everyone. However, there are a number of other tools that work similarly, even if they do not output quite as impressive results:
Text-to-image software, like deepfake videos, has the potential to fundamentally change society and shake faith in the media. Will we still need graphic designers in the future if everyone can describe the desired image with words and the AI then creates it on its own? Do we trust the website that posts pictures of politicians engaging in illegal gambling or worse?
There are several ethical challenges facing text-to-image research. It is very likely that both DALL-E and Imagen are not yet available to the public for this reason. Both tools have an extensive content policy that prohibits certain things, including depictions of violence, nudity, the portrayal of politicians or bullying.
OpenAI has even built a number of deepfake safeguards into DALL-E to prevent it from remembering faces, and the system also rejects uploaded images if they contain realistic faces. The company also uses human reviewers to check images that have been classified as potentially problematic. Until recently, faces were also distorted in the output. This has changed, as DALL-E now creates faces of non-existent people.
With great power comes great responsibility – this definitely applies to text-to-image tools.
Who owns the copyright to AI generated images?
After looking at the different levels of artificial intelligence in connection with images – starting from image optimization up to complete image creation – one question remains: Who owns the copyright for synthetic images?
Until now, copyright in computer-generated works has not been challenged because the program was merely a tool that supported the creative process, much like pen and paper. In the latest forms of artificial intelligence, however, the computer program is no longer just a tool, but makes many of the decisions in the creative process without human intervention (WIPO).
In early 2022, the Copyright Review Board in the U.S. rejected for the second time an application by Steven Thaler, who wanted to claim copyright for images created by an artificial intelligence. The reason given was the lack of human authorship, which is required to establish a copyright claim. The Court has continued to articulate the nexus between the human mind and creative expression as a prerequisite for copyright protection.
Other countries take a different approach. In the UK, for example, the programmer of the artificial intelligence is considered the author.
“In the case of a literary, dramatic, musical or artistic work which is computer-generated, the author shall be taken to be the person by whom the arrangements necessary for the creation of the work are undertaken.” (CDPA 9 (3))
Currently, in many countries, there are either no regulations at all or it is simply not possible for a human to claim copyright for images created by an AI.
Another question that is also unanswered: who is liable for copyright infringement by an artificial intelligence? Legislators will increasingly have to deal with these scenarios in the future, which is why there will certainly be many changes in this area in the coming years.
What is the future of synthetic images?
In this article, we wanted to give you a little glimpse into the world of artificial intelligence in conjunction with images. AI has been a constant part of photo editing for many years now and has also led to a rapid increase in its range of applications lately.
For many people, it is scary to see what is possible these days with a computer and a few lines of code. AI can not only invent fictional people, but create complete reality-based images based on a simple text description.
What impact on society this technology will hold in the future and what methods for detecting AI-generated images will be invented, only time can tell.
One thing is certain, however: artificial intelligence has now reached a point that just a few years ago was depicted in sci-fi movies as a far-off future.
- Published: August 3, 2022
- Updated: November 28, 2023


1%, 4%, 36%?